
Obsah
Většina z vás používá pro svou práci Screaming Frog a pokud testujete věší weby a nemáte neomezeně operační paměti , kterou můžete Screaming Frogu přidělit – hledáte řešení. Pokud nechcete přejít jinam, tak se vám může hodit následující návod jak využívat při crawling Google cloud. Tento článek je upravený a aktualizovaný návod od Filla Wiese. Hodně štěstí!
Tomuto článku předcházela německá verze, otištěná v německém časopise Website Boosting, vydaného v tištěné podobě k 25. výročí SearchBrothers.com. Zajímáte-li se o SEO a rozumíte německy psanému textu, velice vám doporučuji právě tento magazín.
Screaming Frog SEO Spider je jeden z těch vzácných nástrojů, bez kterých se nikdo, kdo se zabývá SEO neobejde. Jedná se bez diskuze o prvotřídní crawler, dokud ovšem nenarazíte na jeho omezení. Je vám ta situace povědomá? Že vám při práci v Screaming Frog SEO Spider náhle dojde operační paměť? A že ani žádná přídavná paměť Screaming Frog SEO Spider nenasytí, pokud prohledáváte opravdu rozsáhlé stránky? Existuje řešení: Spouštějte Screaming Frog SEO Spider v cloudu, nejlépe na infrastruktuře Google Cloud.
Screaming Frog SEO Spider
Pro většinu SEO specialistů je Screaming Frog SEO Spider králem v oblasti prohledávání a analýzy webových stránek z hlediska SEO. Program Screaming Frog SEO Spider, který vyvíjí britská agentura Screaming Frog, je také jedním z mála, ne-li jediným crawlerem, běžícím na Ubuntu a dalších systémech postavených na platformě Debian. Screaming Frog SEO Spider lze použít k mnoha rozličným účelům, jako jsou on-page analýza a kontrola odkazového profilu.
Největší slabinou Screaming Frog SEO Spider však je, že při prohledávání obsáhlejších stránek nebo rozsáhlých seznamů URL adres vyžaduje příliš operační paměti. I když tým vývojářů neustále pracuje na vylepšeních, můžete pro Screaming Frog SEO Spider použít infrastrukturu Google disponující velkým množstvím operační paměti. A to je chvíle, kdy přichází ke slovu Google Compute Engine.
Google Compute Engine
Pro případ, že byste to nevěděli, Google umožňuje pracovat s velkou zátěží na virtuálních strojích běžících na infrastruktuře Google. Služba se jmenuje Google Compute Engine a nabízí možnost pronájmu výpočetních zdrojů na základě případů užívání.. Google Compute Engine je sice ještě ve fázi velmi intenzivního vývoje, ale už nyní je v oblasti výpočetních zdrojů založených na cloudu vážným konkurentem služeb Amazon Cloud a Windows Azure Cloud. Cenami může Google Compute Engine též velmi směle konkurovat, a tak jde o vynikající alternativu k dobře zavedené službě Amazon Cloud.
A abych byl jako SEO konzultant a bývalý Google Support Engineer a člen týmu Google Search Quality upřímný, představa využití hardware a infrastruktury Googlu pro prohledávání webových stránek se mi opravdu zamlouvá. Začněme tedy nastavením nové instance Google Compute Engine s programem Screaming Frog SEO Spider.
Instalace Google Cloud SDK
Nejdříve ze všeho je třeba nainstalovat Google Cloud SDK na svůj počítač. Je to poněkud zdlouhavé, ale stačí to udělat jednou. Jelikož je o poznání jednodušší spustit instalaci na některé distribuci Linuxu jako jsou Ubuntu nebo Mac, zaměřím se v tomto článku pouze na postup pro počítače používající Linux. Chcete-li Google Cloud SDK nainstalovat lokálně na počítač s Windows, použijte tento návod.
Nejprve otevřete terminál a přesvědčte se, že máte nainstalovaný curl. To zjistíte jednoduše tak, že v terminálu zadáte „curl” a počkáte, zda budete vyzváni k instalaci. Pokud je vyžadována instalace, můžete ji v případě Ubuntu spustit tímto příkazem:
sudo apt-get install curl
Když už víte, že máte nainstalovaný curl, spusťte v terminálu následující příkaz (z domovského adresáře). Tím stáhnete a nainstalujete Google Cloud SDK:
curl https://sdk.cloud.google.com | bash
Dalším krokem je oznámit terminálu, že už je Google Cloud SDK nainstalován. Jsou dvě možnosti, jak to udělat. První je přímočařejší: zavřete a znovu otevřete terminál. Druhým způsobem je spuštění následujícího příkazu (bez nutnosti restartovat terminál – řetězec <bash-profile-file> nahraďte příslušným názvem souboru, například „bashrc”):
source ~/.<bash-profile-file>
Jakmile jste tak učinili, lze použít následující příkaz pro ověření, že je Google Cloud SDK nainstalován:
gcloud version
Pokud příkaz nevrátí chybu a ukáže výsledek s číslem verze a seznamem nainstalovaných nástrojů, je Google Cloud SDK správně nainstalován a na vašem systému funguje.
Ověření nainstalované verze Google Cloud SDK
Dalším krokem je přihlášení vašeho počítače ke službám Google Cloud. To vám umožní posílat do Google Cloud příkazy pro správu služeb Google Cloud. Na terminálu spusťte tento příkaz:
gcloud auth login
V závislosti na tom, zda máte prohlížeč nainstalovaný na lokálním počítači se otevře nové okno prohlížeče a budete vyzváni, abyste Google Cloud SDK povolili přístup k vašemu Google účtu (můžete být nejprve vyzváni k přihlášení ke svému Google účtu). Můžete být rovněž vyzváni ke vložení odkazu z terminálu do prohlížeče a dokončení celého procesu tímto způsobem. Po přijmutí se zobrazí potvrzení: „You are now authenticated with the Google Cloud SDK.”
Mezitím vás terminál vyzve ke vložení projektového identifikačního čísla pro Google Cloud. Prozatím pouze stiskněte Enter, k tomuto nastavení se za chvíli vrátíme. Šlo-li vše dobře, obdržíte na terminálu zprávu, že jste přihlášeni pomocí svého Google účtu.
Google Developer Console
Dalším krokem je přejít na Google Cloud Console pro vývojáře. Tato webová stránka je určena pro správu služeb Google Cloud, včetně Google Compute Engine.
Nejdříve je potřeba vytvořit nový projekt. Klikněte na tlačítko s nápisem „Create Project“ v horní části stránky. Vyskočí okénko, kde můžete svůj projekt pojmenovat a nastavit mu identifikační kód (Project ID). Název projektu není podstatný, protože se používá pouze v Google Cloud Console. Zadejte zkrátka jen „Screaming Frog”.
Identifikační kód projektu je naproti tomu velice důležitý, neboť slouží k identifikaci projektu a jeho odlišení od všech ostatních uživatelů Google Cloud Services. Pokud se tedy neřídíte tím, co vám navrhuje Google (kliknutím na malou šipku vpravo v poli pro zadávání zobrazíte více návrhů od Google) , může vám dát trochu práce najít pro projekt volný a unikátní identifikační kód. Já pro tento projekt používám identifikační kód „screaming-frog-wb”.

Vytvoření nového projektu v Google Cloud
Po stisknutí tlačítka Create budete přesměrování na přehledovou stránku projektu, v našem případě https://console.cloud.google.com/home/dashboard?project=screaming-frog-wb (všimněte si, že identifikační kód se použije URL adrese).
Nyní se dostáváme k důležitému kroku: potřebujeme povolit billing. Google Compute Engine nemá žádné volné kvóty. Pro používání Google Compute Engine je tedy nutné povolit billing. Více informací o cenách Google Compute Engine najdete zde.


Billing povolíte tak, že kliknete na Settings v levé liště přehledové stránky. První zobrazená volba by nyní měla být Billing, s šedým tlačítkem „Enable billing”. Připravte si platební kartu a klikněte na tlačítko. Vyberte svou zemi, vyplňte svou adresu, v případě nutnosti také údaje k platbě daně, dále telefonní číslo a jméno. Pokračujte zadáním dat ke platební kartě. Po dokončení tohoto kroku jste připraveni začít používat Google Compute Engine.
Tip: Jakmile povolíte billing a začnete používat služby Google Cloud, zobrazí se v pravém horním rohu přehledové stránky projektu odkaz pro zobrazení podrobností k odhadovaným cenám za právě probíhající měsíc.
Po vytvoření projektu a povolení plateb se pojďme blíže zabývat nastavením, které vám zajistí přístup k rozličným nástrojům. Klikněte na volbu „API manager“ v nabídce na levé straně přehledové stránky projektu. Nyní se podívejte na sekci týkající se Google Compute Engine a zapněte tyto služby kliknutím na tlačítko „Enable API”. Ve výběru možností zvolte CLI api.
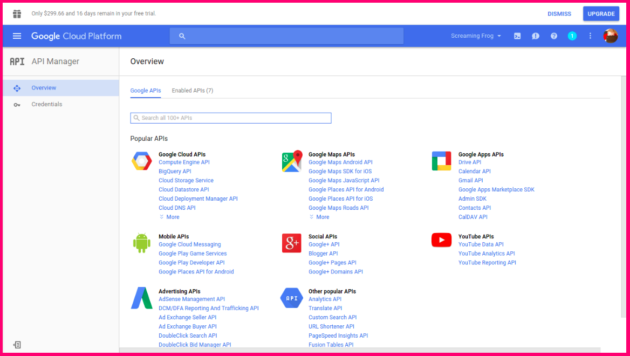
Povolení API pro Google Cloud Services
Všechny dosavadní kroky se vztahovaly k nastavení počítače a projektu. Žádný z nich tedy nebude nutné absolvovat znovu, pokud se nerozhodnete pro změnu počítače nebo nastavení nových projektů.
Jste připraveni spustit na infrastruktuře Google první virtuální stroj?
První spuštění Google Compute Engine
Znovu otevřete terminál a spusťte následující příkaz (řetězec <project-id> nahraďte svým unikátním identifikačním kódem k projektu – pro naše účely řetězcem screaming-frog-wb):
gcloud config set project <project-id>
Jakákoli činnost spojená s Google Cloud SDK bude nyní provedena jako součást projektu Screaming Frog, včetně vyúčtování plateb.
Pro potvrzení, že na počítači nic jiného neběží spusťte v terminálu následující příkaz:
gcloud compute instances list
Výsledkem by mělo být zobrazení prázdné tabulky.
Zatím to jde dobře. Nyní můžete vytvořit novou instanci pomocí následujícího příkazu:
gcloud compute instances create screaming-frog-test –image debian-7 –machine-type f1-micro
Všímavý čtenář zaznamenal, že jsem v příkazu vynechal část „-wb”. To proto, že „screaming-frog-test” slouží k identifikaci dané instance v rámci projektu „screaming-frog-wb”.
Terminál vás nyní vyzve k zadání zóny. V této fázi můžete použít zónu us-central1-a. Typ stroje f1-micro (nejlevnější) a obraz debian-7 jsme zvolili v parametrech příkazu. Nyní se začne vytvářet instance. Jakmile se vytvoří, můžete spustit tento příkaz pro přihlášení pomocí SSH (příkazový řádek):
gcloud compute ssh screaming-frog-test
Poznámka: Můžete být vyzváni k nastavení klíčů SSH. Jednoduše se řiďte podle instrukcí a použijte heslo, které si zapamatujete.
Blahopřeji! Nyní jste připojeni k virtuálnímu stroji na infrastruktuře Google. To můžete potvrdit tak, že se přepnete do projektu na Google Cloud Console nebo zadáním tohoto příkazu v terminálu vašeho lokálního počítače:
gcloud compute instances list
V této fázi instanci znovu vypneme. Přesvědčte se, že jste stále připojeni k instanci přes SSH a spusťte v terminálu následující odkaz:
exit
Tím se odhlásíte a odpojíte svůj počítač od dané instance. Nyní přejděte do Google Cloud Console, zvolte daný projekt, vyberte volbu Compute Engine, pak VM Instances, klikněte na odkaz screaming-frog-test a jděte na spodní část stránky. Zde můžete kliknout na Delete pro případné vymazání instance. Pokud tuto možnost využijete, nezapomeňte také vymazat boot disk pro screaming-frog-test.
Jiným způsobem vymazání je vypnutí a zapnutí instance a zadání tohoto příkazu v terminálu:
gcloud compute instances delete screaming-frog-test –delete-disks boot
Budete vyzváni k potvrzení vymazání instance a boot disk. Po potvrzení se Google Compute Engine pokusí vymazat instanci virtuálního stroje a boot disk. Znovu potvrdit, že je instance vypnutá (a negeneruje tedy žádné další náklady) můžete pomocí tohoto příkazu na vašem lokálním počítači:
gcloud compute instances list
Poznámka: Služby Google Cloud mohou být někdy pomalé a příkazy v terminálu mohou vypršet. Pokud to nastane, můžete postup vymazávání sledovat v Google Cloud Console.
Nastavení instance Screaming Frog
Nyní, když je nastaven projekt v Google Cloud a vy znáte základní příkazy k práci s instancemi Google Compute Engine, nastává čas vytvořit instanci pomocí Screaming Frog SEO Spider.
Nejprve vytvořte instanci spuštěním následujícího příkazu v terminálu (všimněte si, že pro tuto instanci používám jako unikátní identifikátor „screaming-frog”):
gcloud compute instances create screaming-frog –image debian-7 –machine-type n1-standard-8 –scopes storage-rw
Zvolte si libovolnou zónu (mějte na paměti, že evropské zóny jsou o něco dražší) a stroj s dostatkem RAM (Já obvykle používám n1-standard-8) a obraz debian-7 (nejdůležitější!).
Všímavý čtenář si mohl všimnout přidaného příznaku pro –scopes storage-rw ve výše uvedeném příkazu. Tento příznak vám později umožní ukládat instalaci a ušetří vám čas, kdykoli použijete tento obraz Screaming Frog SEO Spider na Google Compute Engine.
Když už je instance spuštěna, přihlaste se k instanci přes SSH pomocí tohoto příkazu:
gcloud compute ssh screaming-frog
Nyní, když jste přihlášeni k instanci, se potřebujete přepnout do rootu spuštěním tohoto příkazu v terminálu:
sudo -s
Když jste nyní v rootu, je třeba aktualizovat softwarové balíčky. Spusťte následující příkaz:
apt-get update
Poté použijte tento příkaz k instalaci nezbytných programů:
apt-get install tightvncserver xfce4 xfce4-goodies xdg-utils openjdk-6-jre software-properties-common python-software-properties
Proces trvá několik minut a zahrnuje instalaci VNC serveru a minimalistického uživatelského rozhraní, které je nenáročné na zdroje. Po výzvě ke konfiguraci klávesnice jednoduše použijte automatickou volbu (klávesou Tab přejděte na „OK“ a potvrďte klávesou Enter).
V této chvíli by také mohlo být užitečné spustit následující příkaz, a vyhnout se tak budoucím varovným upozorněním, že nemáte nastavené lokální údaje:
dpkg-reconfigure locales
Budete vyzváni k výběru lokálního nastavení. Nejsnazší (ale zároveň časově nejnáročnější) možností je zvolit „All Locales” (klávesou TAB se přesuňte na volbu „OK”). Poté vyberte nabízenou možnost „None” pro standardní nastavení systémového prostředí. Vyplnění vám může trvat několik minut a je plně dobrovolné.
Jakmile je proces dokončen, je třeba nastavit v systému dalšího uživatele pod jménem „vnc”. To provedeme spuštěním následujícího příkazu:
adduser vnc
Po vyzvání vložte bezpečné heslo o délce osmi znaků. Ostatní hodnoty můžete přeskočit stisknutím klávesy Enter a zvolit tak přednastavené možnosti. Pomocí Y potvrďte správnost zadaných informací.
Nyní nastavte uživateli heslo. Nejprve se přepněte do nového uživatele pomocí tohoto příkazu:
su vnc
Spusťte následující příkaz:
vncpasswd
Po výzvě odpovězte (N)o na otázku, zda si přejete vložit heslo určené pro vstup pouze pro prohlížení. Doporučuji použít stejné osmimístné heslo, které jste si nastavili při vytváření uživatele.
Tím vytvoříte nový adresář v adresáři /home/ VNC uživatele a nastavíte heslo, jež bude později sloužit pro VNC připojení k instanci. Mějte na paměti, že toto heslo nesmí být delší než osm znaků.
Nastavení spouštěcích skriptů
Když jsme nyní nastavili VNC uživatele, je třeba nainstalovat několik skriptů, které budou sloužit ke spouštění VNC serveru při každém startu nebo restartu instance. Nejprve se přepněte zpět do root uživatele zadáním následujícího příkazu:
exit
Nyní použijte tento příkaz ke stažení prvního spouštěcího skriptu:
wget http://filiwiese.com/files/vncserver -O /etc/init.d/vncserver
Poté zadejte tento příkaz ke stažení druhého spouštěcího skriptu:
wget http://filiwiese.com/files/xstartup -O /home/vnc/.vnc/xstartup
Když máme stažené a nainstalované spouštěcí skripty, můžeme zadáním následujícího příkazu zprovoznit VNC server:
chown -R vnc. /home/vnc/.vnc && chmod +x /home/vnc/.vnc/xstartup
sed -i ‘s/allowed_users.*/allowed_users=anybody/g’ /etc/X11/Xwrapper.config
chmod +x /etc/init.d/vncserver
Nyní restartujte instanci zadáním tohoto příkazu:
reboot
SSH připojení se v tuto chvíli ukončí. Může to trvat minutu nebo dvě, ale poté se k instanci přes SSH znovu připojte spuštěním následujícího příkazu:
gcutil ssh screaming-frog
Tímto příkazem se znovu přepněte do uživatele root:
sudo -s
Nyní spustíme službu VNC zadáním dvou následujících příkazů:
update-rc.d vncserver defaults
service vncserver start
Blahopřeji, nyní můžete použít libovolný program zvládající VNC k připojení k instanci přes VNC.
Instalace Screaming Frog SEO Spider
Před připojením přes VNS pojďme dokončit instalační proces instalací Screaming Frog SEO Spider a knihovny Oracle Java. K tomu použijeme následující příkazy:
echo “deb http://ppa.launchpad.net/webupd8team/java/ubuntu trusty main” | tee /etc/apt/sources.list.d/webupd8team-java.list
echo “deb-src http://ppa.launchpad.net/webupd8team/java/ubuntu trusty main” | tee -a /etc/apt/sources.list.d/webupd8team-java.list
apt-key adv –keyserver hkp://keyserver.ubuntu.com:80 –recv-keys EEA14886
apt-get update
apt-get install oracle-java8-installer
Na vyzvání zvolte OK a pomocí navigačních kláves vyberte YES. Dále nastavte Oracle Java jako primární knihovnu Java:
apt–get install oracle–java8–set–default
Pro ujištění, že se knihovna Oracle Java 8 úspěšně nainstalovala spusťte následující příkaz:
java -version
Vrátí se tento výstup:
java version “1.8.0_25”
Java(TM) SE Runtime Environment (build 1.8.0_25-b17)
Java HotSpot(TM) 64-Bit Server VM (build 25.25-b02, mixed mode)
Když máme nainstalovanou knihovnu Oracle Java, potřebujeme před instalací poslední verze Screaming Frog SEO Spider ještě přidat knihovnu „ttf-mscorefonts-installer”.
add-apt-repository “deb http://http.debian.net/debian wheezy main contrib non-free” && apt-get update && apt-get install ttf-mscorefonts-installer
Nyní spusťte následující příkaz pro stažení Screaming Frog SEO Spider:
wget http://www.screamingfrog.co.uk/products/seo-spider/screamingfrogseospider_3.1_all.deb
Následující příkaz pak nainstaluje Screaming Frog SEO Spider pro všechny uživatele:
dpkg -i screamingfrogseospider_3.1_all.deb
Může se objevit chyba kvůli závislosti, které se říká „zenity”. To vyřešíte spuštěním tohoto příkazu:
apt-get -f install
Vrátí se výstup (v dlouhém výpisu):
Setting up screamingfrogseospider (3.10) …
A je to! Screaming Frog SEO Spider je nainstalován!
Poznámka: V době, kdy čtete tento článek už může být pro Ubuntu vydána novější verze Screaming Frog. Na webových stránkách Screaming Frog SEO Spider najdete odkaz na nejnovější verzi pro Ubuntu.
Připojení přes VNC
Nyní se připojíme k VNC serveru. IP adresu, kterou potřebujete pro přístup k instanci zjistíte tak, že se odhlásíte z SSH připojení a na lokálním stroji spustíte níže uvedený příkaz. Externí adresa se vypíše v tabulce.
gcloud compute instances list
Než budete v terminálu pokračovat, je nutné aktualizovat pravidla instance pro firewall. Ve svém prohlížeči jděte do Google Cloud Console, zvolte projekt, zvolte Compute Engine, v nabídce po levé straně vyberte Networks a klikněte na odkaz „Default”. Zde přidáme nové pravidlo. Najděte na stránce Firewalls, klikněte na odkaz „Create new” a do formuláře doplňte následující údaje:
Name: vnc
Protocols & ports: tcp:5800,5900-5909
Pro ostatní pole použijte přednastavené hodnoty a klikněte na modré tlačítko „Create”. A new firewall rule will be created that will allow you to access the VNC server.
Nyní se připojte k instanci pomocí VNC na Ubuntu. Zkuste použít program Remmina a následující údaje:
hostname: <external-ip>:5901
password: <the-8-character-password>
Příklad konfigurace VNC připojení
Je-li to potřeba, můžete si nainstalovat program Remmina spuštěním tohoto příkazu na vašem lokálním počítači:
sudo apt-get install remmina
Jakmile je spuštěno VNC připojení, vyskočí na obrazovce okénko, kde zvolíte možnost „Use default config”.
Dále vytvořte na ploše zkratku pro Screaming Frog SEO Spider. Klikněte pravým tlačítkem na pozadí plochy, vyberte „Create Launcher” a do okénka vyplňte tyto informace:
Name: Screaming Frog
Command: screamingfrogseospider %f
Klikněte na tlačítko Create. Na ploše se vytvoří se nová zkratka. Dvojklikem na tuto zkratku spusťte Screaming Frog SEO Spider. V tomto okamžiku je užitečné zadat před opětovným zavřením programu licenční informace.
Poznámka: Při psaní tohoto názvu se možná sama nabídne volba „Create Launcher Screaming Frog SE…”. V takovém případě ji potvrďte. Kliknutím na tlačítko ICON ještě před použitím tlačítka „Create” a po výběru nabízené možnosti si můžete zvolit standardní ikonu pro spouštění Screaming Frog SEO Spider.
Příklad vytvoření nové ikony pro spuštění programu a výběru nabízené možnosti pro Debian
Nyní už jste téměř na konci instalace. Zbývá poslední krok, kterým je nastavení vyhrazené paměti pro RAM instance, kterou máme k dispozici. To bude fungovat pouze v případě, že jste už přes VNC spustili Screaming Frog SEO Spider alespoň jednou. Vraťte se do terminálu a připojte se znovu přes SSH pomocí tohoto příkazu:
gcutil ssh screaming-froggcloud compute ssh screaming-frog
Nyní přepněte uživatele spuštěním následujících příkazů:
sudo -s
su vnc
Použijte tento příkaz k otevření konfiguračního souboru Screaming Frog SEO Spider určeného pro nastavení vyhrazené paměti:
pico /home/vnc/.screamingfrogseospider
Podle typu stroje, který jste vybrali pro instanci změňte číslo 512 na číslo co nejbližší maximální RAM pro instanci. Pokud například používáte n1-standard-8, je dostupná RAM 30GB – aktualizujte tedy číslo 512 na 29000. Zavřete soubor, uložte změny pomocí CTRL-X a na otázku, zda si přejete uložit změnu vyrovnávací paměti odpovězte Y(es). Později se jakékoli změně velikosti typu stroje pro instanci ujistěte, že je číslo upraveno na velikost menší než dostupná RAM.
Toto je také správná chvíle pro spuštění Screaming Frog SEO Spider a změnu konfigurace, například nastavení User Agent, Speed, Crawl atd. Po dokončení nezapomeňte nastavit současnou konfiguraci jako výchozí.
V tomto okamžiku jsou nastavené VNC i Screaming Frog SEO Spider. Nyní je třeba zajistit, abyste nemuseli všechny tyto kroky neustále opakovat při spuštění každé další instance Screaming Frog SEO Spider a VNC. To uděláme uložením celého nastavení do vlastního obrazu.
Záloha vaší instance
Abyste celé nastavení mohli zálohovat, přihlaste se ze svého počítače k instanci spuštěním tohoto příkazu:
gcloud compute ssh screaming-frog
Poté použijte následující příkaz pro spuštění zálohování:
sudo gcimagebundle -d /dev/sda -o /tmp/ –log_file=/tmp/abc.log
Tento příkaz vytvoří obraz všech nastavení a programů nainstalovaných v předchozích krocích. Výstupem tohoto příkazu bude dlouhé hexadecimální číslo, obsahující název a umístění právě vytvořeného obrazu, například:
/tmp/<long-hex-name>.image.tar.gz
Dočasně si toto dlouhé číslo někam zkopírujte, protože ho využijete v následujících krocích.
Když je nyní vytvořen obraz zálohy, je třeba jej uložit do Google Cloud Storage. Nejprve se přihlaste a nastavte přístup k Google Cloud Storage pomocí následujícího příkazu:
gsutil config
Držte se instrukcí a otevřete nové okno prohlížeče s poskytnutou URL adresou, přijměte žádost o povolení a vložte zkopírovaný autorizační kód do zadávacího pole poskytnuté URL. Poté vložte identifikační číslo projektu, v našem případě screaming-frog-wb, a potvrďte klávesou Enter.
Dále pomocí následujícího příkazu vytvořte v Google Cloud Storage nový bucket s unikátním názvem:
gsutil mb gs://<bucket-name>
Poznámka: Nahraďte <bucket-name> svým názvem, který je unikátní v rámci všech bucketů v Google Cloud Storage. Tady možná budete muset být trochu tvořivější, než se vám podaří najít název, který ještě není použitý.
Dalším krokem je zkopírování obrazu do bucketu v Google Cloud Storage spuštěním tohoto příkazu:
gsutil cp /tmp/<long-hex-name>.image.tar.gz gs://<bucket-name>
Poznámka: Nezapomeňte v předchozím příkazu správně nahradit části <long-hex-name> a <bucket-name>.
Jakmile je dokončeno kopírování obrazu zálohy do bucketu v Google Cloud Storage, odpojte SSH připojení k instanci spuštěním příkazu
exit
a přidejte svůj vlastní obraz zálohy do sbírky Images collection na Google Cloud Project. To učiníte v terminálu svého lokálního počítače pomocí tohoto příkazu:
gcloud compute images create screaming-frog-image –source-uri gs://<bucket-name>/<long-hex-name>.image.tar.gz
Po dokončení tohoto procesu je obraz zálohy bezpečně uložen v Google Cloud Storage a bude od příštího vytvoření instance již bude dostupný v rámci projektu. V případě potřeby je obraz možné vymazat pomocí Google Cloud Console nebo spuštěním následujícího příkazu:
gcloud compute images delete screaming-frog-image
Je rovněž možné ověřit, že byl obraz zálohy úspěšně vytvořen. Přepněte se do Google Cloud Console, vyberte projekt, zvolte Compute Engine, a v nabídce na levé straně vyberte Images. V seznamu dostupných obrazů už byste měli najít „screaming-frog-image”.
V tomto okamžiku je vše nastaveno a uloženo,. Je tedy možné deaktivovat současnou instanci příkazem:
gcloud compute instances delete screaming-frog –delete-disks boot
Tímto deaktivujete instanci a smažete disk, čímž se vyhnete jakýmkoli dalším nákladům (s výjimkou těch, spojených s uložením vlastního obrazu) až do doby, než budete znovu potřebovat použít Screaming Frog SEO Spider na Google Compute Engine. To potvrdíte spuštěním tohoto příkazu:
gcloud compute instances list
Příkaz by měl opět vrátit prázdnou tabulku.
Používání vaší přednastavené instance
Když jste nyní připraveni používat Screaming Frog SEO Spider na Google Compute Engine, otevřete terminál na svém počítači a spusťte následující příkaz:
gcloud compute instances create screaming-frog –image screaming-frog-image –machine-type n1-standard-8
Po vyzvání zvolte libovolnou zónu (mějte na paměti, že evropské zóny jsou o něco dražší), stroj s dostatkem RAM (ideálně n1-standard-8 nebo vyšší) a obraz „screaming-frog-image”. Jakmile instance běží, poznamenejte si externí IP adresu přidělenou této instanci.
Dále spusťte VNC program, například Remmina, a přípojte se k instanci pomocí externí IP adresy na portu 5901 a nastaveného osmimístného hesla.
Spusťte Screaming Frog SEO Spider a začněte prohledávat…
Navýšení prostoru na disku
Až začnete instanci používat, brzy zjistíte, že je prostor v základní instanci omezen na 10 GB, z nichž je ještě přibližně 1 GB použit pro instalaci operačního systému, programu Screaming Frog, VNC a jeho závislostí. Potřebujete-li více prostoru na disku, můžete jej navýšit pomocí přídavného stálého disku (second persistent disk).
Nejjednodušším způsobem navýšením prostoru na disku na instanci Google Compute Engine je přejít v prohlížeči do Google Cloud Console, vybrat svůj projekt, poté Compute Engine, dále do Disks a kliknout na červené tlačítko „New Disk”. V zobrazeném formuláři zvolte stejnou zónu (Zone), jako používáte pro instanci (toto je nesmírně důležité, neboť z instance běžící v odlišné zóně se není možné k disku připojit) a zvolte blank disk (prázdný disk) jako Source Type. Co se týká velikosti, doporučuji držet se nastaveného 500 GB disku, alespoň v případě, že si ještě nejste jisti, zda využijete větší prostor. Možná vás překvapí, jak rychle se druhý disk zaplní.
Vytvoření nového stálého prázdného disku
Po vytvoření disku jděte v Google Cloud Console do své instance a disk k ní připojte.
Připojení nového stálého disku
Po vyzvání vyberte volbu read/write.
Volba režimu stálého disku
Nyní uvidíte, že je disk připojený k vaší instanci (pokud ne, zkuste instanci vypnout a znovu spustit). Bude možné se k němu připojit přes příkazový řádek. Dále se přihlaste do své instance přes SSH a přepněte se do uživatele root spuštěním těchto příkazů:
gcloud compute ssh screaming-frog
sudo -s
Nyní identifikujte označení disku tímto příkazem:
fdisk -l
S největší pravděpodobností se vám zobrazí zpráva informující o tom, že druhý disk (např. /dev/sdb) nemá platnou tabulku segmentu.
Kontrola stavu připojených disků pomocí příkazu fdisk
To vyřešíme přidáním tabulky segmentu novému disku pomocí tohoto příkazu:
fdisk /dev/sdb
Po vyzvání napište ‘n’, vyberte ‘e’ a stiskněte Enter pro uložení do výchozího nastavení. Po dokončení ukončete fdisk napsáním ‘q’.
Vytvoření nové tabulky segmentu na disku pomocí příkazu fdisk
Dalším krokem je zformátování disku pomocí tohoto příkazu:
mkfs.ext3 /dev/sdb
Nyní je možné připojit disk k instanci, čímž se stane dostupným přes příkazový řádek nebo průzkumník ve VNC a bude připraven pro ukládání dat. Pro připojení disku spusťte následující příkaz:
mkdir /mnt/disk1
mount /dev/sdb /mnt/disk1
Aby mohli všichni uživatelé disk a jeho obsah používat, je třeba upravit přístupová práva pomocí tohoto příkazu:
chmod 777 /mnt/disk1
Při přidávání dalších souborů na disk bude možná třeba práva nadále aktualizovat tak, aby ostatní uživatelé (např. vnc) mohli číst a zapisovat do těchto souborů. To je možné udělat v příslušném adresáři. Tam se dostanete přes příkazový řádek, kde rovněž spustíte tento příkaz:
chmod 777 *
Poznámka: Obvykle se považuje za nepříliš dobrý nápad používat „chmod 777” pro soubory na jakémkoli vzdáleném serveru, ale jelikož je naše instance pouze dočasná a přistupuje se k ní přes VNC a SSH, považuji to za malé riziko v porovnáním s tím, jak to vše usnadní. Pokud zamýšlíte nechat instanci běžet delší dobu, doporučuji prozkoumat jiná řešení, jako například použití skupin uživatelů.
Disk může být nyní použit pro ukládání dat z průzkumu pomocí Screaming Frog SEO Spider a podobně.
Mějte na paměti, že disk pracuje nezávisle na instanci. Když vymažete instanci, disk se automaticky nesmaže. Díky tomu je možné disk zachovat (s uloženými daty) v cloudu Google a znovu jej v budoucnu připojit k další instanci. Je však potřeba vědět, že nesmazaný disk se pojí s dalšími výdaji.
Instalace Dropboxu
Pokračujme instalací Dropboxu. Důvodem pro instalaci Dropboxu je potřeba možnosti přenášet soubory mezi instancí a počítačem. Dropbox je pro tento účel ideálním nástrojem. Nejprve si stáhněte instalační soubor Dropboxu pro Debian pomocí tohoto příkazu:
wget https://www.dropbox.com/download?dl=packages/debian/dropbox_1.6.0_amd64.deb -O dropbox.deb
Dalším příkazem nainstalujte Dropbox pro VNC uživatele:
dpkg -i dropbox.deb
Kvůli závislosti „python-gtk2” se vykáže chyba. Tu vyřeší spuštění jiného příkazu:
apt-get -f install
Instalace Dropboxu je nyní dokončena.
Nyní se přihlaste k VNC připojení a jděte do nabídky Applications v levém horním rohu, zvolte Internet a vyberte Dropbox. Tím stáhnete Dropbox pro uživatele VNC. Budete vyzváni k vytvoření nového účtu pro Dropbox nebo přihlášení ke stávajícímu účtu. Vytvořte si nový účet, čímž zamezíte stažením obsahu z vašeho stávajícího Dropboxu do instance. Po dokončení instalace a registrace k Dropboxu vytvořte v Dropboxu novou složku a nastavte sdílení s vaším stávajícím účtem (pokud nějaký máte). Nyní můžete sdílet soubory mezi počítačem a instancí pomocí Dropboxu. Máte-li na disku prostor navíc, můžete také změnit cestu ke složce Dropbox na nový disk a mít tak k dispozici více prostoru pro synchronizaci souborů.
Přenos dat přes SSH
Pokud účet Dropboxu použitý ve vaší instanci nemá členství PRO, velice rychle vám může dojít prostor v Dropboxu pro přenos souborů. Data můžete přenášet také přes SSH pomocí příkazu gcloud compute copy-files.
Ze svého lokálního počítače můžete nahrávat data do instance Google Compute Engine příkazem:
gcloud compute copy-files /home/user/local-file <instance_name>:/home/remote-user/remote-file
Pokud má tedy tento příkaz nahrávat například soubor ve formátu ZIP na druhý disk připojený k instanci screaming-frog, bude funkční příkaz vypadat takto:
gcloud compute copy-files /home/fill/local.zip screaming-frog:/mnt/disk1/
Nebo je možné stahovat data z instance pomocí SSH pomocí příkazu:
gcloud compute copy-files screaming-frog:/mnt/disk1/remote-file /home/user/
A znovu, pokud má příkaz stahovat na lokální počítač ZIP soubor z druhého disku připojenému k instanci screaming-frog , bude mít funkční příkaz tuto podobu:
gcloud compute copy-files screaming-frog:/mnt/disk1/remote.zip /home/fill/
Více informací k používání pull a push (a dalších příkazů) v nástroji gcutil najdete zde.
Jak zajistit nepřerušení procesů spuštěných z příkazových řádků
Instanci můžete používat také pro zpracování velkoobjemových souborů přes příkazový řádek nebo jiné procesy příkazového řádku. Když se odpojíte s instancí používající SSH, například kvůli přerušení internetového připojení, procesy spuštěné z příkazového řádku se ukončení a může dojít ke ztrátě dat. Tomu můžete jednoduše zamezit instalací a používáním nástroje tmux.
Nejprve se připojte k instanci přes SSH a spuštěním následujících příkazů nainstalujte tmux:
gcloud compute ssh screaming-frog
sudo -s
apt-get install tmux
exit
Nyní můžete použít tmux po otevření přes následující příkaz. V již běžícím shellu s příkazovým řádkem se otevře nový shell s příkazovým řádkem:
tmux
Všechny příkazy spuštěné v shellu tmux dále poběží i po odpojení. Když potřebujete opustit okno tmux, stiskněte ‘Ctrl-B’ a napište na klávesnici ‘d’. Tím odpojíte shell tmux od okna shellu. Do okna shellu tmux se v případě potřeby (například pro kontrolu stavu běžících procesu) můžete znovu přepnout tímto příkazem:
tmux attach
Více informací o nástroji tmux najdete zde, zde nebo zde.
Závěr
Ačkoli může začátek práce s Google Compute Engine zpočátku působit odstrašujícím dojmem, přišel jsem na spoustu výhod (rychlost a čistá výpočetní rychlost) používání Google Compute Engine pro zpracování velkého objemu dat a prohledávání URL adres. Velice doporučuji najít si i další informace a experimentovat se službami Google Cloud, zejména z pohledu SEO konzultanta.
Moc díky za aktualizaci článku a korekci Davidovi Karbanovi bez kterého by tento článek nevznikl. Pokud se vám Google cloud nelíbím, můžete dle návodu Mikea Kinga zkusit to samé na Amazon Cloudu. Budu rád, když o tom pak napíšete, rád odkážu:-)
Další články, které vás budou zajímat




Jsem konzultant online marketingu a specializuji se na SEO a inbound marketing. Od roku 2009 jsem pracoval jako senior SEO konzultant pro největší klienty agentur Ataxo a H1.cz. Úspěšně publikuji, školím a přednáším o online marketingu, který doopravdy miluju. Jsem důsledný, zodpovědný, kritický, se smyslem pro detail.
V případě, že máme ke vzdálenému VPSku přístup pžes veřejnou IP adresu a nejen přes GCloud příkazy a na firewallu povolíme SSH port, tak se můžeme připojovat klasicky obyčejným ssh a využít třeba i sshfs pro přimountování svazků na vzdáleném stroji.
Co se týče toho připojení přes vnc, tak standardně je vnc nešifrovaným protokolem, kde se heslo i všechny zadané klávesy posílají v plaintextu, tak pozor na to.Je možné se ale např. přes Remminu připojit na VNC, ale přes ssh tunel. Tj. Remmina se připojí na SSH port serveru, vytvoří si šiforvaný tunel a na VNC se už připojuje jakoby na localhost, ale veškeré spojení pak jde tím SSH tunelem. Může být nutné v konfiguraci SSH serveru povolit tunelování.
Pokud ale jde “jen” o 32 GB RAM, tak to minimálně na desktopu už není kdovíjaký problém. Nacpat 32 GB nebo dokonce víc do notebooku je samozřejmě pořád trochu oříšek. Což je trochu zvláštní, když mi vesele funguje 16 GB na i5 z roku 2011, dnes je 2016 a moc jsme se od té doby v tomhle neposunuli…
Parádní návod Pavle, určitě vyzkouším, protože zrovna nedávno jsem potřeboval udělat analýzu jednoho rozsáhlého e-shopu a nechal jsem to procházet SF celou noc a druhý den jsem zjistil, že je to teprve na 50 %. Zrychlí to i procházení stránek?
Bohužel to ne:-(
Doporučuji testovat SiteAnalyzer – bezplatný program pro audit a technickou analýzu webu. Zároveň je soubor funkcí prakticky ne méně než placené protějšky.
Bezplatný nie je ani zďaleka.